Load balancing is a crucial part of modern network infrastructure. We’re in a world where most websites and web applications cope with increased load by scaling out — that is, running multiple copies of a single application or service and then dividing incoming traffic between them. Load balancers divide incoming requests equitably, so no single server is overwhelmed. They increase application reliability by providing the ability to distribute thousands of requests between multiple instances. Load balancers are redundant by nature, so if a request fails, it can be rerouted to working servers.
Organizations can scale an application using two approaches: horizontal scaling and vertical scaling. Vertical scaling means powering up instance specifications in terms of CPU, RAM, and storage. Alternatively, organizations achieve horizontal scaling by increasing the number of instances. In that scenario, the load balancer adds value by simultaneously sending requests to all the available instances.
Different types of load balancers work in different ways to address multiple levels of the OSI model. The OSI model divides networks into seven layers, ranging from physical hardware at layer 1 to end-user applications at layer 7. Most load balancing occurs at layer 2 (L2) and layer 3 (L3), so that’s where we’ll be focusing in this article.
L2 is where data transmission occurs between machines connected to the same physical or virtual network. Hardware and software operating at L2 handle intranet data flow and error control.
Communication between two different networks or subnets, such as sending network requests across the internet, happens at L3. Hardware and software operating at L3 find the best physical path for the message and route traffic accordingly. Protocols operating at L3, like Transmission Control Protocol (TCP) and User Datagram Protocol (UDP), typically create packets of data on the sending side of a request and then reassemble them on the receiving side. L3 is responsible for flow and error control in communication between networks.
Let’s dive into these two layers, their relative advantages, and how they can work together to provide optimal load balancing performance.
Routing on Level 3 Versus Switching on Level 2
The primary difference between the layers is the way routing and switching works. L3 comes into the picture when routing takes place between multiple networks. L3 routing makes it possible for network requests to travel smoothly from one machine to another, even if the request must pass through multiple routers or computers to reach its destination.
Switching, however, occurs at L2 within a single network. L2 uses the hardware MAC address of each computer connected to a local network and does not use IP addresses or TCP or UDP ports. In contrast, modern L3 routing almost exclusively uses IP addresses — although less common technologies like IPX and AppleTalk can also be routed at L3.
In other words, L2 switching uses MAC addresses to switch the packets from a source port to a destination port, maintaining a MAC table to map the network relationships. L3 switching technology, commonly known as routing, maintains an IP routing table to find the shortest path from a source to a destination.
Now that we have a little context about L2 and L3 and how routing and switching works, it’s time to learn about L2 and L3 load balancing.
Load Balancing on L2 versus L3
Sometimes, too many requests go to a single server, causing it to become overloaded and unresponsive. In cases like these, you might use several copies of the same application or service to help share the load, but you still must find a way to divide the traffic between them. That’s where a load balancer comes in. A load balancer splits the load between the available servers and devices to minimize overhead on a single server or device.
At layer 2, load balancing can distribute traffic among the machines on the same network. But, as we discussed, it only routes traffic based on MAC addresses. It’s impossible to route traffic to another device on a different network using L2 load balancing. There are many scenarios when this kind of load balancing is helpful. One such use case divides the bandwidth equally to all devices within the network.
In contrast, L3 load balancers operate at a higher level, making it possible to route traffic using IPv4 and IPv6 addresses. Organizations use them to distribute the load across different virtual machines. They ensure high availability and reliability by circulating requests among servers or VMs.
Many L3 load balancers also enable developers and DevOps engineers to choose from various algorithms to perform load balancing effectively. Some standard L3 load balancing algorithms include round robin, weighted round robin, fewest connections (least connection), IP hash, consistent hashing, least time, and equal-cost multi-path (ECMP). Let’s examine a few of them.
A Quick Look at L7 Load Balancing
In contrast to L2 and L3 load balancers, L7 load balancers are software that operates at the application layer. Popular L7 load balancing tools include Nginx and HAProxy. Many of them are open source, making it easy to add SSL termination and implement new protocols like HTTP/3.
L7 load balancers can also use extra information available at the application layer to carry out complex and intelligent load balancing. They can read the content of incoming HTTP(S) and use that data to route the request directly to where it needs to go. Most L7 load balancers also can define rules and targets to achieve the expected routing.
The main disadvantage of L7 load balancers is that they usually act as proxies, so they must maintain two open connections: one to the machine that made the request and one to the target machine that is serving the request. L2 and L3 load balancers, in comparison, simply forward packets to their destination.
Load Balancing Techniques and Algorithms
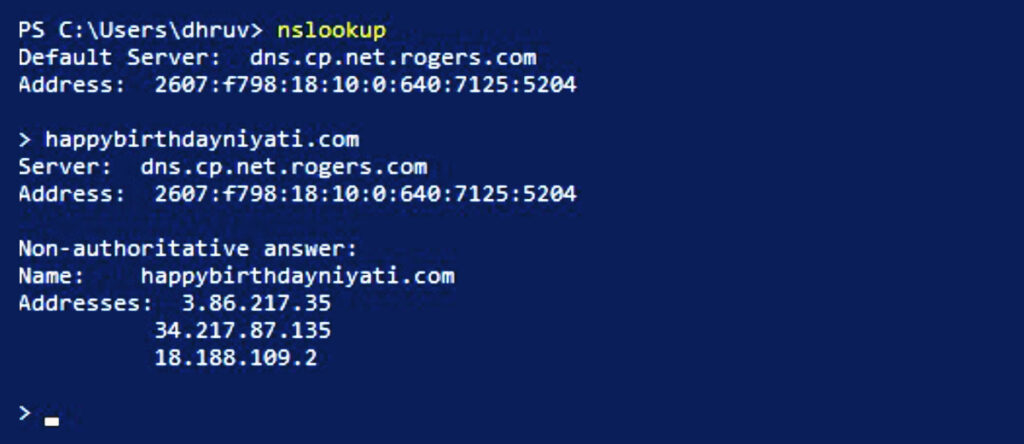
The most basic approach to load balancing is the round-robin DNS method. This method creates multiple DNS records for the same host, pointing to different servers. So, for instance, if we do nslookup on one of our domains, it returns three A records associated with it.
Though this approach is easy to implement, there are disadvantages to using it. First, it doesn’t check whether the configured server is running. In other words, the request will still go to the non-working server if configured in DNS management. Another drawback is that the effect is not instantaneous — time to live (TTL) plays a massive role. That means the user may be doing something on Server A, refresh the page, and the load balancer redirects them to another server.
Server load balancing (SLB) is another advanced approach to load balance the request to multiple servers. SLB has more features and benefits than the round-robin DNS method. Unlike round-robin DNS, SLB supports health checks, which means the request will only go to a healthy server instance.
It also supports the mechanism of connection draining, ensuring that current requests complete before removing a server from the load balancer. If the connection draining feature is enabled, after deregistering the instance, it immediately stops new requests to that instance but allows existing requests to complete. We explain various techniques and algorithms associated with the SLB below.
Round robin is the most straightforward and widely-used load balancing algorithm. It distributes requests to the server pool in rotation regardless of server characteristics. In other words, if you have three servers, the first request goes to the first server, the next request goes to the second server, and the final request goes to the third server.
Weighted round robin is an upgraded version of the round robin algorithm. It eliminates a key limitation of the round robin algorithm by allowing an administrator to assign a weight to each server in the pool. It is most useful when you do not have identical servers. Different generations of servers have different capabilities, and this algorithm enables us to bridge the gap between distributed traffic and multiple servers spanning different generations. The weighted round robin algorithm divides requests according to the weight assigned to the server.
Fewest connections (least connection), as the name suggests, sends the client’s request to the server with the fewest active connections. This algorithm may also consider the relative computing power of each server to determine which server to pick.
IP hash uses the client’s IP address to generate a unique hash key and then uses that key to associate the IP address with a specific server. As long as the list of back-end servers doesn’t change, requests from a specific IP address will always go to the same server.
This can be useful if you’re trying to implement session persistence (a.k.a. sticky sessions), but it’s important to note that if you add servers to the load balancer, requests may no longer hash to the same server as before. IP hash load balancing can be ineffective if you receive a disproportionate number of requests from a small number of IPs. Ideally, we should distribute these requests among multiple servers to prevent server overload, but with IP hash balancing, all requests from an IP will always be sent to the same server.
Consistent hashing reduces the drawbacks of the IP hash method. Consistent hashing uses a more elaborate hashing algorithm (which may still incorporate the request’s IP address, but may also use additional information such as URL or HTTP headers) to ensure that a user’s requests continue to go to the same server even if new servers are added to the load balancer.
This approach makes it easier to implement session persistence because you won’t break existing user sessions if you add new servers to the load balancer. It’s also helpful if you’re setting up your own CDN or cache. You could, for example, use consistent hashing to ensure that all requests asking for .mp4 files goes to a subset of servers you’ve set up for serving video assets.
Least time intelligently identifies and assigns the fastest server to the client. During the health checks, the SLB measures the response time of each server — the slower servers get fewer connections on the assumption that response time is a proxy for server load.
Equal cost multi-path (ECMP) offers a significant bandwidth increase by balancing the load between multiple routing paths from the router to the source machine, ensuring that no single network route becomes overloaded with traffic. It takes two steps. The first step is finding the best path from the host to the destination, and the second step is hashed routing.
The second step uses a hash function to get a 5-tuple hash that typically contains source IP, destination IP, protocol, source port, and destination port. The resulting hash value determines which server to route the request to.
Why Are Load Balancers Important?
We briefly discussed the different techniques and algorithms that we can use with load balancers. However, load balancers do more than just distribute traffic in the server pool. The modern load balancer also manages the user’s active session. This functionality — known as session persistence or sticky sessions — means the load balancer can connect the same user to the same server over an extended period.
For example, say a user adds an item to a shopping cart and accidentally closes their browser. Load balancers can intelligently identify and redirect users to the same server to continue from where they left off. This can improve efficiency as it allows applications to store user session data in memory on a single server rather than keeping it in a database or key-value store like Redis.
Load balancers can also check the underlying server’s status using regular health checks and let the administrator know if any server fails. Even in cases of failure, load balancers can stop directing traffic to that server until the health check is green again. This feature helps reduce downtime and eliminate system failure.
Load balancers also add a protective layer to the application without changing the application’s underlying structure. Load balancers can improve security by protecting against distributed denial-of-service (DDoS) attacks. They also enable adding an optional authentication layer.
Load balancers make it easy to add SSL/TLS because you only have to add a certificate to the load balancer instead of adding it to every back-end server. They even make it easy to add support for new protocols like HTTP/3 and QUIC even if your back-end servers don’t yet support the new protocol.
Finally, many well-known load balancers are open-source and maintained by a large community. Modern load balancers support most of the features we’ve covered in this article. Organizations can even use multiple load balancers to get the most availability and scalability. It’s a common practice to mix and match L3 and L7 load balancing to achieve the best results.
Conclusion
In this article, we learned about the basic idea of the OSI model, examined how packets are switched and routed, explored L2 and L3, and discussed different load balancing algorithms along with some of the problems they solve.
Understanding load balancing is an integral part of understanding web application performance — whether you’re controlling load balancing directly or just using your cloud or edge provider’s load balancing behind the scenes.