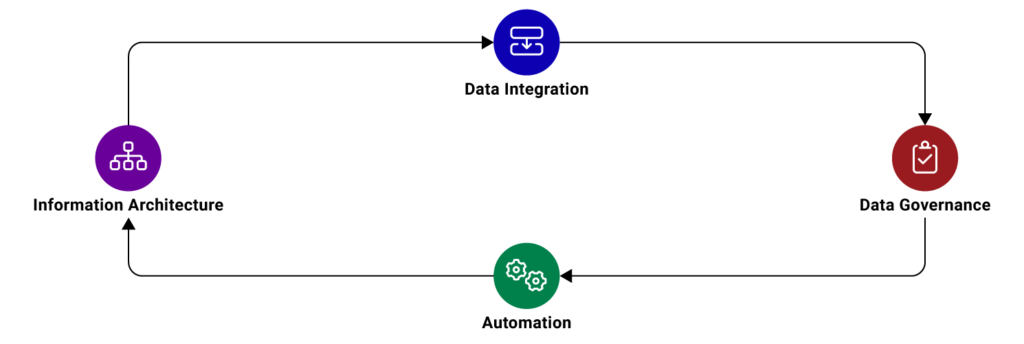
Throughout the years, there have been several changes in the field of data management. Companies used to employ basic technologies to handle data; then, there was a time when organizations turned data into insights using the cloud and visualization tools. However, there have always been concerns about scalability, and data formatting, among other issues.
Now with enhanced technologies and tools, data has become a crucial part of development, marketing, sales, leadership, and customer success. But all this data can be a lot to manage. To help, you can use DataOps.
Inspired by DevOps, DataOps is an integrated data strategy aimed at increasing collaboration, integration, and automation between managers and consumers. Its goal is to help businesses deliver the correct data to the right people at the right time.
In simple terms, DataOps is the DevOps of data analytics. By accelerating the creation and deployment of automated data operations, DataOps provides high-quality, on-demand data to corporate clients.
Overview
DataOps uses agile development techniques. The agile approach is a style of project management that divides a project into stages. With agile methodology, you can enhance productivity, increase transparency, optimize tasks, and improve user experience.
Why Do You Need DataOps?
Since the data is in several systems and platforms, acquiring access to and control over the data, and identifying the correct data, becomes a challenging task. Data pipelines have expanded with the demands of data analysts, scientists, and data-hungry applications, leading to issues like team miscommunication, a lack of collaboration, inflexible data architecture, and more.
Here are some key reasons why you need DataOps:
Increasing Data Quality
Poor data quality erodes the confidence of the overall analytics system, putting the entire project at risk. Data errors can occur anytime due to various factors, including duplicate data, schema changes, and feed failures. With DataOps, maintaining quality data is prioritized, thereby eliminating — or at least minimizing — complications that stem from poor data quality.
Avoiding Manual Operations
Integration, monitoring, and analysis are time-consuming and inefficient. As a result, solving data-related difficulties necessitates not just technologies but also modifications in the underlying analytical processes. DataOps improves the agility of all data operations by automating the entire data lifecycle.
Facilitating Collaboration
DataOps facilitates cross-team cooperation and allows them to collaborate in real-time. As a result, the metrics are more accurate. DataOps helps you collect data from various sources, automatically integrate fresh data into pipelines, centralize data, and automate pipeline changes, allowing developers, data scientists, and others within your organization to be on the same page.
How DataOps Works
DataOps aims to orchestrate data, technologies, applications, and environments from start to end to provide repeatable outcomes. In general, DataOps solutions achieve this purpose by managing, creating, deploying, and executing analytics in production.
Stages in DataOps
The process can be pretty complicated, encompassing hundreds of activities. However, there are usually four phases:
Data ingestion: This stage analyzes and processes data and puts it into a system after retrieving it from multiple sources.
Data transformation approaches to get insights: This stage filters and enhances the data and creates data models to satisfy the application’s demands.
Data analysis: At this point, the analytics team may collect additional data to reach reliable findings or use various analysis approaches to get insights.
Data visualization: This stage is when you create presentations or visualizations to more efficiently convey data insights.
A DataOps approach to these phases applies agile methodology. A DataOps approach automates as much as possible and makes implementation as simple as possible. As a result, data engineers have more time to consider the meaning of the data and respond to business needs.
DataOps and CI/CD
DataOps is a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and consumers across an organization.
Because DataOps stems from and is related to DevOps, CI/CD and DataOps share some similarities. The DataOps pipeline is like the CD in the CI/CD architecture. The most significant difference between CI/CD for DevOps and DataOps is in the deployment of software and data products.
Orchestration
DataOps automates data movement among the following different stages. In this respect, it applies to each step of the data analytics pipeline from beginning to conclusion.
Development
In development, building a new pipeline, updating a data model, or revamping a dashboard all benefit from DataOps in the automated orchestration of data flows from development to testing.
Testing
At this point, it’s critical to examine every part of the data and evaluate it to confirm that the data task’s outputs meet expectations. DataOps tests monitor the data values flowing through the pipeline to catch anomalies or flag data values outside statistical norms. Tests validate new analytics before deploying in the innovation portion of the pipeline. The DataOps architecture encourages checking for data correctness, possible deviations, and mistakes in even the most minor updates.
Deployment
This stage moves data jobs from one environment to the next, pushes them to the next step, or deploys the whole pipeline to production. As with the other stages, the collaborative approach DataOps brings to deployment reduces problems in deployment and ensures data is agile, accurate, and efficient.
Monitoring
Monitoring is required for data quality since it helps data professionals spot inefficiencies, detect abnormal trends, and track change implementation. The collaboration of teams in the DataOps model results in quicker incident responses and bug fixes.
Benefits of DataOps
Now that you know what DataOps is, it’s time to explore its benefits.
More Reliable Error Catching
The output tests employed by DataOps catch incorrectly processed data quickly. Quickly finding incorrectly processed data is crucial because it improves the data quality and prevents errors going downstream where they can create more complex — and often more costly — problems for your business.
Increased Data Productivity
DataOps enables you to create and alter data pipelines quickly and precisely, reducing manual and time-consuming processes and helping you get more value out of data.
Promotes Agile Development
DataOps is based on the Agile project methodology. Implementing DataOps encourages the use of this methodology.
Promotes Automation
The aim of continuous improvement and continuous development is one of the main concepts of Agile methodology. Using a CI/CD pipeline encourages the automation of the work involved, including monitoring, updating, alerting, and much more.
Long Term Direction
DataOps encourages practicing strategic data management regularly. It takes advantage of multi-tenant collaboration to assist clients in negotiating their demands.
Gets More Value out of Data
DataOps platforms provide benefits by breaking down the barriers of working remotely, divisions between groups, and conflicting business goals. Like other types of collaboration, data collaboration stimulates new insights and better ideas and overcomes analytic problems. Although often considered a downstream practice, providing collaboration features for data discovery, augmented data management, and provisioning results in better outcomes. During the time of COVID-19, collaboration has become even more critical.
Best Practices
Now, let’s explore some best practices for creating a DataOps strategy.
Version Control
To manage all their code, software developers use version control systems. Similarly, you must treat data as code. In DataOps, you must centralize data versioning and storage to ensure that data flow components are repeatable and that you can quickly restore a previous working state if something goes wrong.
Performance Benchmarks and Metrics
At each stage of the data lifecycle, you should define performance benchmarks and metrics to help you improve your data.
End-to-End Efficiency
Modern DataOps has been made possible by integrating point solutions into an end-to-end platform. An end-to-end platform provides solutions for a variety of service functions, and it provides a single source of truth. In other words, it’s a centralized data solution. Because an end-to-end solution supplies workflows for each area of a business, it provides an overview of your business.
Communicate
Communicating is essential for team productivity. DataOps is linked to a variety of teams and environments. So, it’s necessary to frequently and thoroughly share changes you’re making to your code, how you’re modifying the development workflow, and how you’re using data.
Automation
Use automation to deal with bottlenecks and data silos. Automate as much work as you, including monitoring, updating, and alerting. However, remember that automation should be applied where it makes the most sense. Automate to optimize where it counts, and not necessarily at every possible opportunity, to be efficient.
Build Slowly
Building incrementally is a fundamental principle of Agile methodology. You should focus on starting quickly with the data subsets and then work on delivering incremental value resulting from feedback from the end-users. The agile data mastering process must be gradual, automated, and collaborative to streamline the formation of data pipelines.
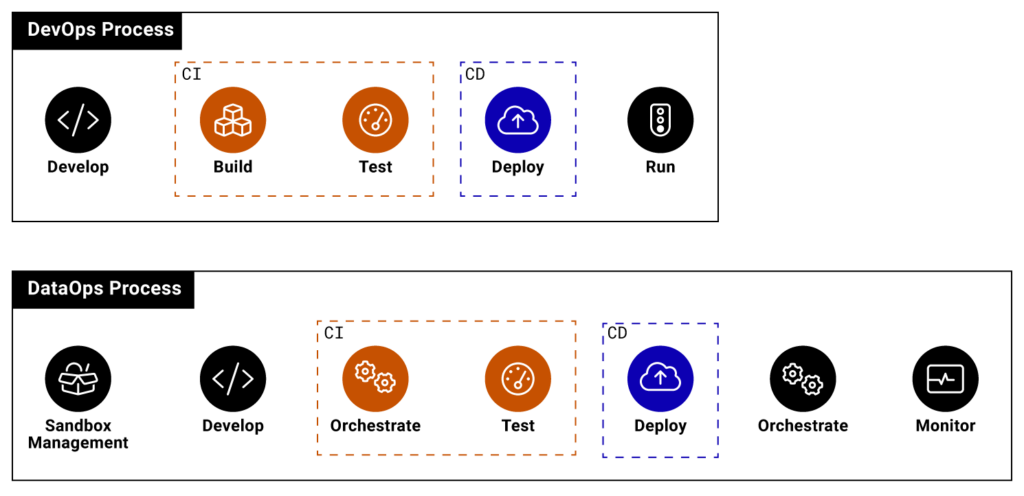
DataOps Versus DevOps
Take a look at the following image. Notice where the DataOps and DevOps overlap and where their processes differ.
Although both DataOps and DevOps overlap in building/orchestrating, testing, and deploying code, these methodologies have some essential distinctions outlined below.
Objective
DevOps aims to reduce the application development lifecycle, increase quality, and encourage cross-team collaboration. DataOps similarly aims to improve product quality, but it does so by specifically aligning data and teams with larger business objectives.
Quality
DevOps works to maintain product quality by removing development obstacles and bottlenecks. The quality of the code is directly mirrored by the quality and efficacy of the development lifecycle. With DataOps, product quality is maintained through extracting high-quality, business-ready data that you can use to measure performance.
Organization
When it comes to internal organization, DevOps and DataOps are somewhat different. With DevOps, development and IT teams are aligned to speed up operations before and after sprints. With DataOps, data citizens are aligned with IT through defined roles. These established roles increase the overall efficiency of collaboration.
Automation
Both DevOps and DataOps prioritize automation — just in different ways. DevOps seems non-stop automation in the software delivery process for server and version configurations. DataOps also seems non-stop delivery, but it’s through data acquisition, curation, integration, and modeling automation.
Agile Capabilities
DevOps practices agile development using frequent deployments and quick recovery from any deployment failures that occur. In DataOps, agile methods are maintained through the improvement of data quality and reduction in time to identify metadata.
Key Takeaways
DataOps is an integrated data strategy aimed at increasing collaboration, integration, and automation between managers and consumers
DataOps aims to help businesses deliver the correct data to the right people at the right time
DataOps aims to orchestrate data, technologies, applications, and environments from start to end to provide repeatable outcomes
Implementing DataOps benefits your organization, including more reliable catching, promoting agile development, long-term direction, and more
DataOps encourages practicing strategic data management regularly. It takes advantage of multi-tenant collaboration to assist clients in negotiating their demands
To improve data management, it’s critical to establish new data governance processes consistent with DataOps